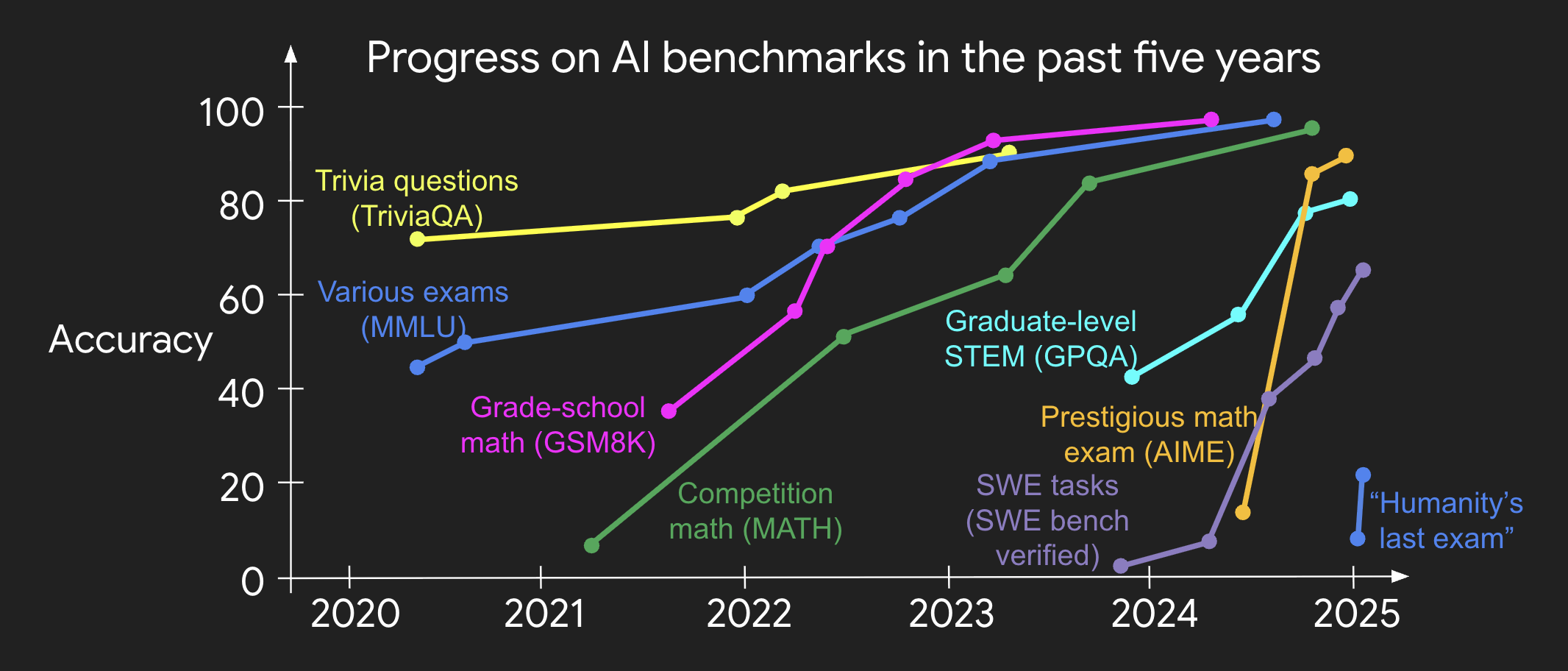
Life lessons from reinforcement learning
Becoming an RL diehard in the past year and thinking about RL for most of my waking hours inadvertently taught me an important lesson about how to live my own life.
One of the big concepts in RL is that you always want to be “on-policy”: instead of mimicking other people’s successful trajectories, you should take your own actions and learn from the reward given by the environment. Obviously imitation learning is useful to bootstrap to nonzero pass rate initially, but once you can take reasonable trajectories, we generally avoid imitation learning because the best way to leverage the model’s own strengths (which are different from humans) is to only learn from its own trajectories. A well-accepted instantiation of this is that RL is a better way to train language models to solve math word problems compared to simple supervised finetuning on human-written chains of thought.
Similarly in life, we first bootstrap ourselves via imitation learning (school), which is very reasonable. But even after I graduated school, I had a habit of studying how other people found success and trying to imitate them. Sometimes it worked, but eventually I realized that I would never surpass the full ability of someone else because they were playing to their strengths which I didn’t have. It could be anything from a researcher doing yolo runs more successfully than me because they built the codebase themselves and I didn’t, or a non-AI example would be a soccer player keeping ball possession by leveraging strength that I didn’t have.
The lesson of doing RL on policy is that beating the teacher requires walking your own path and taking risks and rewards from the environment. For example, two things I enjoy more than the average researcher are (1) reading a lot of data, and (2) doing ablations to understand the effect of individual components in a system. Once when collecting a dataset, I spent a few days reading data and giving each human annotator personalized feedback, and after that the data turned out great and I gained valuable insight into the task I was trying to solve. Earlier this year I spent a month going back and ablating each of the decisions that I previously yolo’ed while working on deep research. It was a sizable amount of time spent, but through those experiments I learned unique lessons about what type of RL works well. Not only was leaning into my own passions more fulfilling, but I now feel like I’m on a path to carving a stronger niche for myself and my research.
In short, imitation is good and you have to do it initially. But once you’re bootstrapped enough, if you want to beat the teacher you must do on-policy RL and play to your own strengths and weaknesses :)
Asymmetry of verification and verifier’s rule
Asymmetry of verification is the idea that some tasks are much easier to verify than to solve. With reinforcement learning (RL) that finally works in a general sense, asymmetry of verification is becoming one of the most important ideas in AI.
Understanding asymmetry of verification through examples
Asymmetry of verification is everywhere, if you look for it. Some prime examples:
Sudoku and crossword puzzles take a lot of time to solve because you have to try many candidates against various constraints, but it is trivial to check if any given solution is correct.
Writing the code to operate a website like instagram takes a team of engineers many years, but verifying whether the website is working properly can be done quickly by any layperson.
Solving BrowseComp problems often requires browsing hundreds of websites, but verifying any given answer can often be done much more quickly because you can directly search if the answer meets the constraints.
Some tasks have near-symmetry of verification: they take a similar amount of time to verify as to write a solution. For example, verifying the answer to some math problems (e.g., adding two 900-digit numbers) often takes the same amount of work as solving the problem yourself. Another example is some data processing programs; following someone else’s code and verifying that it works takes just as long as writing the solution yourself.
Interestingly, there are also some tasks that can take way longer to verify than to propose a solution. For example, it might take longer to fact-check all the statements in an essay than to write that essay (cue Brandolini's law: “The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.”). Many scientific hypotheses are also harder to verify than to come up with. For example, it is easy to state a novel diet (“Eat only bison and broccoli”) but it would take years to verify whether the diet is beneficial for a general population.
Improving asymmetry of verification
One of the most important realizations about asymmetry of verification is that it is possible to actually improve the asymmetry by front-loading some research about the task. For example, for a competition math problem, it is trivial to check any proposed final answer if you have the answer key at hand. Another great example is some coding problems: while it’s tedious to read code and check its correctness, if you have test cases with ample coverage, you can quickly check any given solution; indeed, this is what Leetcode does. In some tasks, it is possible to improve verification but not enough to make it trivial. As an example, for a problem like “Name a Dutch soccer player”, it would help to have a list of the famous Dutch soccer players but verification would still require work in many cases.

Verifier’s rule
Why is asymmetry of verification important? If you consider the history of deep learning, we have seen that virtually anything that can be measured can be optimized. In RL terms, ability to verify solutions is equivalent to ability to create an RL environment. Hence, we have:
Verifier’s rule: The ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI.
More specifically, the ability to train AI to solve a task is proportional to whether the task has the following properties:
Objective truth: everyone agrees what good solutions are
Fast to verify: any given solution can be verified in a few seconds
Scalable to verify: many solutions can be verified simultaneously
Low noise: verification is as tightly correlated to the solution quality as possible
Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
It’s not hard to believe that verifier’s rule holds true: most benchmarks that have been proposed in AI are easy to verify and so far have been solved. Notice that virtually all popular benchmarks in the past ten years fit criteria #1-4; benchmarks that don’t meet criteria #1-4 would struggle to become popular. Note that although most benchmarks don’t fit criteria #5 (a solution is either strictly correct or not), you can compute a continuous reward by averaging the binary reward of many examples.
Why is verifiability so important? In my view, the most basic reason is that the amount of learning that occurs in neural networks is maximized when the above criteria are satisfied; you can take a lot of gradient steps where each step has a lot of signal. Speed of iteration is critical—it’s the reason that progress in the digital world has been so much faster than progress in the physical world.
AlphaEvolve
Perhaps the greatest public example of leveraging asymmetry of verification in the past few years is AlphaEvolve, developed by Google. In short, AlphaEvolve can be seen as a very clever instantiation of guess-and-check that allows for ruthless optimization of an objective, which has resulted in several mathematical and operational innovations.
A simple example of a problem optimized by AlphaEvolve is something like “Find the smallest outer hexagon that fits 11 unit hexagons.” Notice that this problem fits all five desirable properties of verifier’s rule. Indeed, my belief is that any solvable problem that fits those five properties will be solved in the next few years.
One thing about the types of problems solved by AlphaEvolve is that it can be seen as “overfitting” to a single problem. In traditional machine learning, we already know the labels in the training set and the significant test was to measure generalization to unseen problems. However, in scientific innovation, we are in a totally different realm where we only care about solving a single problem (train=test!) because it’s an unsolved problem and potentially extremely valuable.
Relation to P = NP
One related but different concept is the open question in computer science of whether P = NP. While both P = NP and verifier’s rule discuss asymmetry of verification, verifier’s rule does not make any claims about the time it would take for AI to solve the problem. In fact, in many of the above cases, such competition math problems, it takes far more computation to solve the problem than to verify a solution given that we already have the answer key.
Moreover, verifier’s rule is even broader in scope than P = NP because verifier’s rule also applies to non-computational tasks. For example, verifier’s rule would claim that AI would eventually be able to optimize non-computational endeavors like finding the best catalyst to speed up a chemical reaction, or the best aerodynamic car design for the fastest quarter-mile time, provided that we design the systems to measure those endeavors quickly and at scale.
Implications
Once you’ve learned about it, you’ll notice that asymmetry of verification is everywhere. It’s exciting to consider a world where anything we can measure will be solved. We will likely have a jagged edge of intelligence, where AI is much smarter at verifiable tasks because it’s so much easier to solve verifiable tasks. What an exciting future to consider.
For more related reading, I liked [this blog post] by Alperen Keles.
AI research is a max-performance domain
A recent clarity that I gained is viewing AI research as a “max-performance domain”, which means that you can be world-class by being very good at only one part of your job. As long as you can create seminal impact (e.g., train the best model, start a new paradigm, or create widely adopted benchmarks), it doesn’t matter if you’re incompetent at adjacent skills. For example, I have seen game-changing AI researchers have horrendous presentation skills, terrible political awareness, and who never think about their career progression. Heck, I even know a top AI researcher who probably wouldn’t pass a basic coding interview. But it doesn’t matter. Exceptional ability at a single thing outweighs incompetence at other parts of the job.
In max-performance domains, you don’t even need to be good at your one thing in a consistent way. An AI researcher can have tens of failed projects per year and still be successful if they produce a seminal work every few years. The metric is the best five works in your career, not the average.
A dangerous thing in max-performance domains is placing too much emphasis on role models. That’s because you don’t know whether you’re mimicking the good characteristics or not. For example, a top AI researcher can make a bad political move that turns out OK for them because of who they are. Or they can make a bold, unsubstantiated statement and expect other people to listen. But if anyone else had done the same thing, the outcome would be opposite.
Another way to view max-performance domains is that they have exponential upside and very little downside. That’s why interviews are especially useless in domains like AI research, because they tend to severely punish mistakes and don’t capture exponential value. An RL expert doesn’t need to know how SVMs work and probably hasn’t thought about it in years. A top AI infra engineer might lack basic knowledge about post-training data practices.
In my view it’s a luxury to work in a max-performance domain. Failure is allowed and stress is usually self-imposed. A thousand years ago, very few humans worked in max-performance domains, but now the opportunity is more available. Technology may have played a role in this shift, and with the progression of AI, hopefully more of humanity can move into max-performance domains.
(If you're wondering about what an example of a non-max-performance domain would be, it's any career where you must have both strengths and also basically no weaknesses. For example, a defender in soccer might cost their team the entire game with a single mistake. A piano player must master all parts of their concerto well, not just a single part.)
Dopamine cycles in AI research
There is a dopamine cycle in doing AI research that is pretty interesting.
Every day you wake up and you think about what experiment to run. You think thing X matters so you decide to improve it or ablate it. Then you write the code and pay some compute to find out the answer. Then you get dopamine or confusion depending on whether the result matched expectations.
For experiments that are small scale you can get several reward signals quickly and develop your intuition. Other times you make a big bet that is non-obvious or controversial and go through a period of hard work, dopamine starvation, and uncertainty to do it. If it works out it's a immense high but if it fails it's natural to be consumed by helplessness.
Sometimes there is an element of ego. You may believe in X or not, and keep working to find evidence to support it or excuses for why it doesn't apply in that experiment. There can be an underlying urge to either to prove your abilities or to show that you’re still relevant in the quickly changing landscape. Science is supposedly objective but the reality is that there is a huge social aspect to it, and respect of peers is an valuable reward signal to seek.
That’s how I feel about it, at least. Every day is a small journey further into the jungle of human knowledge. Not a bad life at all—one i’m willing to do for a long time.
Successful language model evals
Everybody uses evaluation benchmarks (“evals”), but I think they deserve more attention than they are currently getting. Evals are incentives for the research community, and breakthroughs are often closely linked to a huge performance jump on some eval. In fact, I’d argue that a key job of the team lead is to dictate what eval to optimize.
What is the definition of a successful eval? I’d say that if an eval is used in breakthrough papers and trusted within the community, then it’s clearly successful.
Here are some of the successful evals of the past five years:
GLUE/SuperGLUE was used by basically all NLP papers in the pre-LLM era (BERT, T5, etc).
MMLU is used by almost all LLM papers. It’s the favorite eval of DeepMind and Google.
GSM8K spurred LLMs for reasoning, and is used in every paper on chain-of-thought.
MATH is also used in most LLM papers.
HumanEval is the classic eval for LLMs for coding.
Obviously this isn’t a comprehensive list—there are other good evals like HellaSwag, SQuAD, etc.
I made two evals that are somewhat popular. MGSM is used in OpenAI’s simple evals, Claude, and Gemini. BBH was used in Claude, Gemini, and Llama. I think they’re decent but not among the best.
One common thing among the successful evals is that a big paper claims some victory using the eval. GLUE was promoted by BERT. MMLU was promoted by Gopher, Chinchilla, and Flan-PaLM. Chain-of-thought prompting claimed a breakthrough on GSM8K. The prowess of Minerva was shown on MATH. HumanEval was attempted by Codex and others.
Going one level deeper, a good score on the eval must mean something significant and easily understandable. For instance, achieving superhuman performance is very understandable. Solving grade-school level math problems is also something people can easily grasp the significance of.
It’s easier to mess up an eval than to make a good one. Most of the non-successful evals make at least one mistake.
If an eval doesn’t have enough examples, it will be noisy and a bad UI for researchers. For example, someone might run the eval over the course of model training and see that it fluctuates wildly from checkpoint to checkpoint. This makes the eval painful for researchers, and they won’t like using it. It’s good to have at least 1,000 examples for your eval; perhaps more if it’s a multiple choice eval. Even though GPQA is a good eval, the fact that it fluctuates based on the prompt makes it hard to use.
Evals should be high quality. If there are a lot of mistakes in your eval, people won’t trust it. For example, I used Natural Questions (NQ) for a long time. But GPT-4 crossed the threshold where if GPT-4 got a test-example incorrect, it was more likely that the ground truth answer provided by the eval was wrong. So I stopped using NQ.
If your eval is too complicated, it will be hard for people to understand it and it will simply be used less. I think the first version of HELM was a great effort, but it had way too many metrics and subsets. It’s critical to have a single-number metric—I can’t think of any great evals that don’t have a single-number metric.
If your eval takes too much work to run, it won’t gain traction even if everything else is good. BIG-Bench is one of my favorite evals, but it is a great pain to run. There were both log-prob evals and generation evals, which required different infra. There were way too many subsets, and some of them had too many examples, so it took a long time. I believe that’s why BIG-Bench didn’t gain much traction, even though it provided a lot of signal.
If an eval is not on a meaningful task, AI researchers won’t deeply care about it. For example, in BIG-Bench Hard we had tasks like recommending movies or closing parentheses properly. These tasks were challenging and trended well with model size, but doing well on them didn’t allow for making a substantive conclusion about the intelligence of the model. Successful evals often measure things central to intelligence, like language understanding, exam problems, or math.
The grading in your eval should be extremely correct. If someone is debugging why their model got graded incorrectly, and they disagree with the grading, that’s a quick way for them to write-off your eval immediately. It’s worth spending the time to minimize errors due to parsing, or to have the best autograder prompt possible.
For the eval to stand the test of time, performance must not become saturated too quickly. For example, GLUE/SuperGLUE got saturated too quickly that it was hard to show big gains, and people stopped using them. Language models also got good at tasks like summarization and translation faster than we could develop good evals for them, and so we stopped measuring those tasks.
Funny enough, it seems like most of the great evals have atrocious names. GSM8K didn’t need the“8K”, and HumanEval doesn’t actually use humans for evaluation (it’s called HumanEval because the problems were created by humans). MATH was too generic, so people started calling it “Hendrycks-math”, which I suppose is a clever way to get people to name an eval after you.
If you want your eval to be successful, you should help people use it. For instance, when I make an eval, I usually offer to run it for other people on their models. If their model does well, they’ll like the eval and promote it. HELM does a great job of trying to evaluate other people’s models for them, and publicizing the results.
It also helps if you can create incentives for people to use your eval. One of the best incentives for people is what their manager values. So it can pay off to get buy-in on your eval from managers within your lab or company, who will ask their reports to run it. When I created MGSM at Google, I collaborated with Dipanjan Das, who was on a different team than me. I worked with him because he’s a fun guy (not to promote the eval), but I think he liked it and it gained some popularity in his team.
LLMs have made evaluations substantially harder. LLMs are massively multi-task and give long responses. Right now there is no single eval that adequately evaluates LLMs. The current popular evals still use very simple grading (either multiple choice, checking a number, or running unit tests). And even those have problems, like deciding on the prompt or parsing the answer. It would be nice if we centered around a single prompt, like zero-shot chain-of-thought. I know it’s not a perfect solution for many reasons, but I think it’s a reasonable price to pay to get everyone on the same page.
One new thrust has been human pairwise ratings of models, such as LMSYS. The generality of these evals is a double-sided sword. They’re powerful because you can get a single number metric for how good a language model is on a general set of prompts, and noise on the sample-level can be averaged out over a large number of samples. The dangerous side of pairwise evals is that you aren’t exactly sure what you’re measuring—for example, it’s not totally clear how much things like feel and style are weighted compared to correctness.
It also became somewhat trendy to do model-generated evaluations. While I tend to find model-generated evals to be finicky, it’s possible to do them well and they can be useful for quick experiments and seeing large jumps in performance. But creating a great eval that stands the test of time takes a lot of care, and I wouldn’t want to risk anything with synthetic evaluations.
An obvious statement is that the topic of the eval dictates how many people will care about the eval. It’s possible to create a very high-quality domain-specific eval (e.g., legal, medical, etc), and in those cases it’s most important to tailor the eval for what is valued by the experts in that domain. However, it’s important to set the correct expectation with yourself about how popular the eval would become. I once made a histopathology image benchmark, and unsurprisingly it has not gained any traction outside medical image analysis and only got 40 citations. That being said, it’s also possible that a domain-specific eval you create can gain more traction once more people realize its importance. For instance, OpenAI invested heavily in LLMs for writing code, and I believe many more people became interested in LLMs for coding after the success of things like Codex and Github CoPilot.
An increasingly important issue with evals is test set contamination. After the creation of a good eval, examples of the eval tend to get propagated into various places in the internet, like arxiv papers, ChatGPT examples, or reddit. One solution to this is to keep the test set hidden, but this approach introduces a lot of friction. Chris Manning had a good suggestion of an eval having both a public test set and a private test set, and monitoring whether any models deviate substantially on those two test sets. This approach balances low friction of testing on the public test set with high trustworthiness in the private test set.
A final thing I have noticed is that the eval you care about says a lot about your identity. A room full of PhDs will likely be interested in the ability for language models to reason about math, code, and physics. Conversely, I have seen user-facing evals like LMSYS to be considered the gold standard by engineers who came from software or product backgrounds. Though I care about both, my personal bent is towards intelligence, since I believe intelligence is the fundamental driver of how AI will interact with humans.
We as a community should invest in evals a bit more, even though it can be painful and is usually not rewarded as much as modeling work. At the end of the day, good evals (with proper buy-in) are the objective function for AI researchers, and they are a powerful way to make an impact on the field.
Six intuitions about large language models
An open question these days is why large language models work so well. In this blog post I will discuss six basic intuitions about large language models. Many of them are inspired by manually examining data, which is an exercise that I’ve found helpful and would recommend.
Language models are pre-trained to simply predict the next word in a corpus of text, and they learn a surprising amount from this. Let’s look at some examples of what they might learn from this next-word prediction task.
Intuition 1. Next-word prediction on large, self-supervised data is massively multi-task learning.
Although next-word prediction is an extremely simple task, when combined with massive datasets, it forces the model to learn a lot of tasks. Consider the following examples of traditional NLP tasks that can be learned by predicting the next word on some text in the corpus.
| Prefix {choice_1, choice_2} | Task |
|---|---|
| In my free time, I like to {run, banana} | Grammar |
| I went to the zoo to see giraffes, lions, and {zebras, spoon} | Lexical semantics |
| The capital of Denmark is {Copenhagen, London} | World knowledge |
| I was laughing the entire time, the movie was {good, bad} | Sentiment analysis |
| The word for “pretty” in Spanish is {bonita, hola} | Translation |
| First grade arithmetic exam: 3 + 8 + 4 = {15, 11} | Math question |
The above tasks are clear-cut but a bit idealized. In reality, predicting the next word involves doing many “odd” tasks. Consider the following sentence:
| Prefix | Next word [task] |
|---|---|
| A transformer is a deep learning architecture, initially proposed in | 2017 [factual recall] |
| A transformer is a deep learning architecture, initially proposed in 2017 | , [comma prediction] |
| A transformer is a deep learning architecture, initially proposed in 2017, | that [grammar] |
| A transformer is a deep learning architecture, initially proposed in 2017, that | relies [impossible task?] |
When you view the data in this way, it is obvious that next-word prediction forces the model to learn a lot about language; not just syntax and semantics, but also things like comma prediction, factual knowledge, perhaps even reasoning. This is an interesting example of how a simple objective, when combined with complex data can lead to highly intelligent behavior (assuming you agree that language models are intelligent).
Intuition 2. Learning input-output relationships can be cast as next-word prediction. This is known as in-context learning.
The past decades of machine learning have focused on learning the relationships between <input, output> pairs. Because next-word prediction is so general, we can easily cast machine learning as next-word prediction. We call this in-context learning (a.k.a. few-shot learning or few-shot prompting). This was pioneered by the GPT-3 paper, which proposed using a natural language instruction following by <input, output> pairs. This is shown in the left image below from the GPT-3 paper.

In the right part of the image above, we can see that increasing the number of examples in context improves performance for a task in the GPT-3 paper. This means that the model benefits from seeing these <input, output> examples.
In-context learning is a standard formulation of using large language models that is convenient because <input, output> pairs were how we did machine learning for the past decades. However, there is no first-principles reason why we continue following <input, output> pairs. When we communicate when humans, we give also them instructions, explanations, and teach them interactively.
Intuition 3. Tokens can have very different information density, so give language models time to think.
It is a fundamental truth that not all tokens are worth the same in terms of information.
Some tokens are very easy to guess and not worth much at all. For example, in “I’m Jason Wei, a researcher at OpenAI working on large language ___”, it’s not so hard to predict “models”. It’s so easy to predict that token that not much information is lost if I omit it.
Some tokens are very hard to guess; they’re worth a lot. For example, in “Jason Wei’s favorite color is ___”, it’s virtually impossible to predict. So that token contains a lot of new information.
Some tokens can also be very hard to compute. For example, in “Question: What is the square of ((8-2)*3+4)^3/8? (A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (”, the next token requires a lot of work (evaluating that expression).
You can imagine that if you’re ChatGPT, and as soon as you have to see the prompt you have to immediately start typing, it would be pretty hard to get that question right.
The solution to this is to give language models more compute by allowing them to perform natural language reasoning before giving the final answer. This can be done via a simple trick called chain-of-thought prompting, which encourages the model to reason by providing an example of a “chain-of-thought” in the few-shot example, as highlighted in blue.
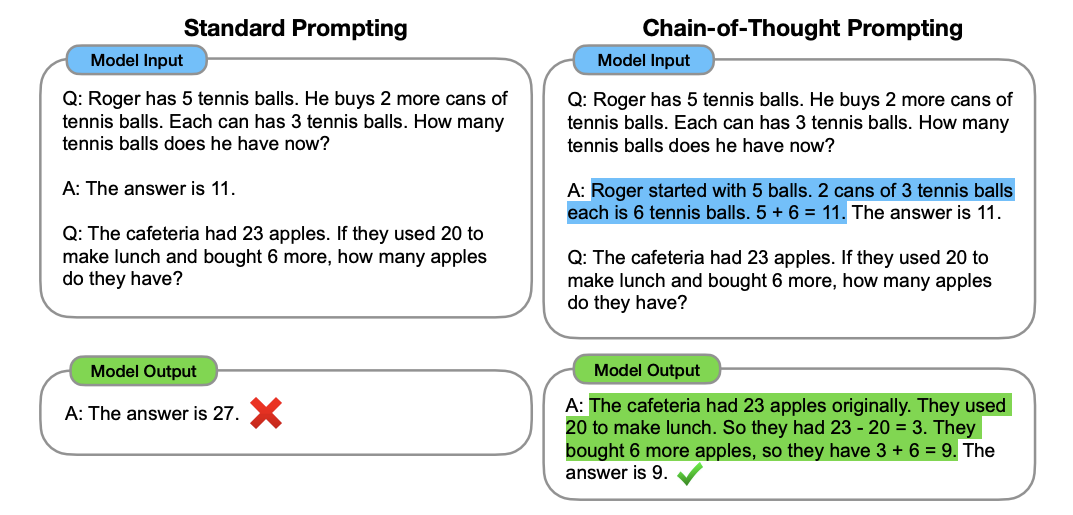
This technique is really useful for improving performance on complicated reasoning tasks that would require humans to spend more than one second solving. For even-more-complicated problems than the simple arithmetic problem shown above, it can help to have the language model decompose the prompt first into subproblems, and then sequentially solve the subproblems (“least-to-most prompting”). This paradigm is powerful because we want AI to eventually be able to solve the hardest problems we face as humans (e.g., poverty, climate change, etc), and being able to reason is a fundamental building block for solving such problems.
The key reason that the above next-word prediction tasks work is scaling, which means training larger neural nets on more data. Obviously it costs a lot of money to train frontier language models, and so the reason we do it is that we have reasonable confidence that using larger neural networks and more data will actually lead to a better model (i.e., performance probably won’t saturate when you increase the model and data size).
Intuition 4. Scaling language models (size and data) is expected to continue improving loss.
The fact that scaling improves performance predictable is called “scaling laws”, for which the left figure below shows that as you increase compute, test loss improves smoothly.

The right figure is another piece of evidence of how loss smoothly improves as you scale up the language model—by tracing the loss curve of smaller models, you can predict GPT-4’s loss using up to 10,000x less compute.
It is an open question why exactly scaling works, but here are two hand-wavy reasons. One is that small language models can’t memorize as much knowledge in their parameters, whereas large language models can memorize a huge amount of factual information about the world. A second guess is that while small language models are capacity-constrained, they might only learn first-order correlations in data. Large language models on the other hand, can learn complex heuristics in data.
Intuition 5. While overall loss scales smoothly, individual downstream tasks may scale in an emergent fashion.
Let’s take a closer look at what exactly happens when loss improves. You can consider overall loss as a weighted average of the massive amount of tasks learned, e.g.,
Overall loss = 1e-10 * (loss of grammar task) + 1e-10 * loss (loss of sentiment analysis task) + …
+ 1e-10 * (loss of math ability task) + …
Now consider your loss going from 4 to 3. Do all tasks get better uniformly? Probably not. Maybe the grammar of the model with loss = 4 was already perfect, so that is saturated, but the math ability improves a lot in the model with loss = 3.
It turns out that if you look at the performance of the model on 200 downstream tasks, you’ll see that while some tasks smoothly improve, other tasks don’t improve at all, and some tasks improve suddenly. Here are eight examples of such tasks, where performance is about random for small models, and increases to well above random once the model size reaches a certain threshold.
The term we use for qualitative changes arising from quantitative changes is “emergence”. More specifically, we call an large language model ability emergent if it is not present in smaller models, but is present in larger models. In such tasks, we often see that performance is about random for small models and well above random for models larger than a certain threshold size, as shown in the figure below.

There are three important implications of emergence:
Emergence is not predictable by simply extrapolating scaling curves from smaller models.
Emergent abilities are not explicitly specified by the trainer of the language model.
Since scaling has unlocked emergent abilities, further scaling can be expected to further elicit more abilities.
Intuition 6. Real in-context learning happens, but only in large-enough language models.
We have seen from the GPT-3 paper that increasing the number of in-context examples improves performance. While we hope that it is because the model actually learns <input, output> mappings from the examples in its context, the improvement in performance could be due to other reasons, such the examples telling the model about formatting or possible labels.
In fact, one paper showed that GPT-3’s performance barely decreases even if you use random labels for the in-context examples. They suggest that performance improvement is hence not due to learning <input, output> mappings, but rather due to the in-context examples teaching things like formatting or the possible labels.
However, GPT-3 is not a super “large” language model compared to the most powerful models today. If we take a more extreme setting of flipped labels (i.e., positive means negative and negative means positive), then we find that large language models strongly follow the flipped labels, while small language models aren’t affected by performance at all. This is shown in the below figure, where performance dips for the large language models (PaLM-540B, code-davinci-002, and text-davinci-002).

The takeaway here is that language models do look at <input, output> mappings, but only if the language model is large-enough.
Closing
I hope the above intuitions were useful despite how basic they are. One theme that is common across many of the intuitions is that you can learn a lot by manually looking at data. I enjoyed doing this recently and highly recommend it :)
Observations from tracking Twitter
In early 2022 I realized that being a good researcher isn’t just about doing good research—it’s also about communicating ideas well and persuading others to engage with them. In other words, research is a highly social activity. In AI research, the social component largely revolves around Twitter, which distributes ideas in many different ways—people discuss research papers, learn about job opportunities, and meet new collaborators. I’ve even heard of some people meeting their romantic partners through Twitter.
So I decided to start using twitter to engage more actively with the AI community. At that time I had just read Peak: Secrets from the New Science of Expertise and was really into the idea of, so I made a somewhat scientific attempt of tracking my “performance” on Twitter in a spreadsheet.
As primary metrics to track, I decided on (1) number of new followers gained per tweet (tracked manually by me logging how # followers before and 24 hours after a given tweet), and (2) number of likes that each tweet got. I didn’t think there was much additional signal in tracking number of retweets or impressions. Also, I only tracked “major” tweets which I put some thought into, and didn’t bother tracking replies or quote tweets that I did spontaneously.
Below is the analysis of the data and some lessons I learned from this exercise, which I hope could be useful to some people who are just starting on twitter or thinking of being more active. Note that my twitter journey is just one example (there are many others). And at the end of all this, as I’ll describe in the last section, I think I ended up falling for some form of Goodhart’s law, and that this type of optimization is the wrong way of approaching twitter.
Followers over time
As an overview, I started with 378 followers on Feb 20, 2022, and ended with 23.6k followers on May 7, 2023. I logged 83 tweets during that period, each represented by a dot in the graph below.

What distribution of followers come from a few popular tweets?
An initial question I had as a Twitter new-joiner was: what distribution of someone’s Twitter followers result from a few popular tweets versus tweeting steadily over time? For me, it was this:
Over time, 12.5k new followers (out of 23k followers) were gained within 24 hours of me making a tweet.
Out of those 12.5k new followers, 8.1k were gained from my top-ten tweets.
My two highest-follower-yield tweets, about joining OpenAI and converting to Research Scientist at Google, led to 3.5k and 1.2k new followers, respectively.
So about one-third of my follower-count came from popular tweets, and the rest came from other tweets and people just deciding to follow me.
Is it possible to forecast how well tweets will do?
Another natural question I had was whether people could typically have a sense of how good a tweet was before they tweeted it, as often the tweets that are the most thoughtful don’t get the most attention [1, 2]. So before each tweet, I tried to forecast how many likes and new followers I would get. Although I wasn’t very accurate, there is definitely a slight correlation. Also there was probably some psychological effect that made my forecasting suboptimal (i.e., I didn’t want to forecast too highly and set myself up for disappointment).

Are there compounding effects from building a follower base?
Another effect I was curious about was whether it would get easier to get likes or new followers after having more followers. My data seems to indicate that there is some compounding effect, but it is small and definitely doesn’t scale linearly (e.g., I didn’t get 4x as many likes per tweet when I had 4x followers). (Note that I also excluded the few tweets with >1k likes or followers to make these plots more readable.)

One thing that I did notice, however, is that after I had some base of followers, I would get more new followers on days when I wasn’t tweeting. This table below shows that from 16k to 23k followers, I gained 61% of my followers on days when I wasn’t tweeting, compared to 41% for my first 6.9k followers.
| Follower range | Total follower gain | Total followers gained from tweets | Followers gained without a recent tweet |
|---|---|---|---|
| 378 to 6.9k | 6.6k | 3.9k (59%) | 2.7k (41%) |
| 16.1k to 23.5k | 7.4k | 2.9k (39%) | 4.5k (61%) |
Likes versus new followers as the optimization metric
A final point that I noticed is that even though the number of likes per tweet is correlated with new followers per tweet, they aren’t the same. Personal posts had a high ratio of new followers per like. On the other hand, posts that were non-personal, such as memes or jokes, could get a lot of likes but didn’t yield a lot of new followers for me.
| Tweet | New followers | Likes | New followers per like |
|---|---|---|---|
| Joining OpenAI | 3.5k | 3.3k | 1.06 |
| Research scientist | 1.3k | 1.7k | 0.76 |
| 2023 new years resolution | 412 | 631 | 0.65 |
| Chinese proverbs in AI | 289 | 2.2k | 0.13 |
| Mountain view joke | 64 | 904 | 0.07 |
| Prompting meme | 85 | 1.2k | 0.07 |
Reflection
Overall, this analysis was an interesting exercise for me to learn the ropes of Twitter, and maybe this data is somewhat helpful to new joiners out there. One big caveat, however, is there are a lot of variables that aren’t accounted for, and these patterns will probably vary substantially from person to person.
For me though, the takeaway at the end of all this is that optimizing for Twitter followers and likes is probably the wrong approach. The main reason is that doing it this way added another “optimization term” to my brain, for which my brain started to backprop and adjust weights to do well on. For example, I noticed that I was a little “too in it”---there were times when I noticed my “free moments” being filled with thoughts on how to write funny jokes or clever tweets that would get a lot of likes. Maybe this would be OK in a perfectly aligned world where the most creative, thoughtful, information-dense tweets get the most likes, but I don’t think we have that perfect alignment yet. So moving forward, I’ve decided to stop tracking tweets, look less at likes and new-followers, and focus on making tweets that are insightful and a positive contribution to the world :)
Common arguments regarding emergent abilities
This blog post doesn’t represent the positions of my employer (past, present, or future).
I’ll review some common arguments that come up when discussing emergent abilities of large language models. Last year we wrote a position paper that defined emergent abilities as “abilities that are not present in small language models but are present in large language models.” I showed that emergent abilities are widely prevalent, and that they are notable for several reasons:
Emergence is not easily predicted by extrapolating scaling curves from smaller models.
Emergent abilities are not explicitly specified by the trainer of the language model (next word prediction “only”).
Since we haven’t tested all possible tasks that exist, we don’t know the full range of abilities that have emerged.
Further scaling can be expected to elicit more emergent abilities.
Since GPT-4, some have argued that emergence is overstated, or even a “mirage”. I don’t think these arguments convincingly debunk the phenomena of emergence, but they are worth discussion and it’s good to examine scientific phenomena with a skeptical eye. I’ll try to restate them in their strongest form and then explain my thinking on them.
Emergence depends on the evaluation metric
Argument: Emergent abilities often occur for “hard” evaluation metrics, such as exact match or multiple-choice accuracy, which don’t award credit for partially correct answers. For instance, multi-step arithmetic requires getting each step right—even failing one step can result in a wrong answer. If you take the same task, but use a “soft” evaluation metric, such as log-probability of the correct target, you might find that performance improves smoothly over time, without significant jumps in performance.
Evidence for this has been shown in multiple papers—the BIG-Bench paper showed that log-probability of targets improves smoothly across scales (Fig. 9 in “Breakthrough behavior is sensitive to details of task specification”), and it was also shown that using a metric like Token Edit Distance on addition or multiplication would appear to improve smoothly instead of in an emergent fashion as seen when using exact match.
Response: While there is evidence that some tasks that appear emergent under exact match have smoothly improving performance under another metric, I don’t think this rebuts the significance of emergence, since metrics like exact match are what we ultimately want to optimize for many tasks. Consider asking ChatGPT what 15 + 23 is—you want the answer to be 38, and nothing else. Maybe 37 is closer to 38 than -2.591, but assigning some partial credit to that answer seems unhelpful for testing ability to do that task, and how to assign it would be arbitrary. Focusing on metrics that best measure the behavior we care about is important because benchmarks are essentially an “optimization function” for researchers.
It’s important to note, however, that finding a “surrogate” metric that improves smoothly is very significant if it gives more information and enables us to predict a more-important emergent metric. I haven’t seen any substantial evidence that exact-match or multiple-choice performance can be predicted using smooth surrogate metrics, though. In our paper, we showed that cross-entropy loss improved even for small model scales where downstream metrics are close to random and did not improve, indicating that improvements in the log-likelihood of the target sequence can be masked by such downstream metrics. But this analysis did not enable us to predict emergent performance by using only smaller models.
It’s currently an open question if surrogate metrics could predict emergence on metrics like exact match or multiple-choice. For instance, given accuracy and cross-entropy loss for a bunch of small models, could you predict the cross-entropy loss for a large model, and then map that to emergent exact-match performance? One might expect that if there is a smooth scaling curve on surrogates, emergence on the downstream metric would eventually occur, but this relationship has not been well-studied enough in terms of how well you’d be able to predict when the emergence would happen, and with what accuracy.
Finally, I want to emphasize that showing smoothness on some metrics for some tasks doesn’t mean this occurs for all tasks. Two examples from the paper are below.
Here, cross-entropy loss is slightly smoother for modified arithmetic, but for IPA transliterate there is still a large kink in cross-entropy loss that breaks the trend and is hard to predict:

Here we can pull multiple metrics available in BIG-Bench that award some partial credit, and we see that the performance still sharply increases at the same threshold:

Emergence is an artifact of the scaling curve plot
Argument [1] [2]: Scaling plots for emergence use an log-scaled x-axis, and if you were to use a linear x-axis scale, the shape of the plot would be smooth.
Response: It's still possible to view emergence on a linear x-axis scale. I plotted Figure 2A from our emergence paper below, and you'll still see the same emergent spike from 7B to 13B (albeit in a less readable way).

In addition to evidence that emergence is still viewable on a linear scale, it’s justified to use a log-scale x-axis by default, since models we train are larger in an exponential fashion. For example, the PaLM model sizes are 8B → 62B → 540B (factor of 8x), and LaMDA model sizes go up by 2x. So a log-scale is appropriate for conveying how we scale models in practice (and this has been done in the literature for many years).
Argument: The paper implicitly claims that we should be able to fit linear-ish curves to plots that have log-x and linear-y axes. Why shouldn't we fit exponentials or some other curves?
Response: It makes sense to also plot log-x and log-y scaling curve, with error rate instead of accuracy on a log-y scaling curve (since accuracy is often 0, and log(0) is negative infinity). However, the shape of the curve stays the same even when you do this.

Emergence is an artifact of not enough model datapoints on the x-axis
Argument [1]: There's a sense in which this definition of emergent (behavior of larger models can't be predicted from smaller ones) has to be too strong—if you sampled the the x axis (number of parameters) densely enough, surely the improvement in accuracy will be continuous or smooth? For example, it seems unlikely that a 1,000,000-parameter model would have 50% (random) accuracy and a model with 1,000,001 parameters would have 90% accuracy.
Response: While this is a reasonable point in theory, we don't have such fine-grained model sizes in practice. But assuming that we did and that the improvement in accuracy would be smooth if you zoomed in enough, I still think there’s a notable phenomena—the performance for the model is flat for models below some certain threshold of parameters, and then above some threshold it starts increasing, and extrapolating the flat points wouldn’t enable us to predict the increasing performance.
Note that this definition is true in an uninteresting way for most tasks for small enough N (e.g., models with one or two parameters would have random performance), and so as Tal Linzen suggested it could be good to specify a particular threshold for N, though I don’t think many people are making this quibble. The overall point is that while some behaviors are very predictable, (e.g., GPT-4's loss on some evaluations can be predicted with models of less than 1,000x compute), other behaviors are not predictable even with 2x less compute. The difference between these two types of behavior are night and day.
A final point
While it’s generally good to be generally skeptical, there seems to be an overwhelming amount of evidence of emergent abilities that (for me) makes it a convincing phenomenon and framing. Even if some emergent abilities are a result of noise, many other instances are very solid. Consider the below plots from the U-shaped scaling and GPT-4 papers: performance actually decreases for several model scales, until it suddenly spikes up. This is a great example of emergence, and I doubt that changing the metric or visualization would make this appear smooth or predictable.

Another popular example of emergence which also underscores qualitative changes in the model is chain-of-thought prompting, for which performance is worse than answering directly for small models, but much better than answering directly for large models. Intuitively, this is because small models can’t produce extended chains of reasoning and end up confusing themselves, while larger models can reason in a more-reliable fashion.

Overall, I’m glad that the idea of emergent abilities is being discussed more and that people are questioning it. I’m especially excited about work that would enable us to predict emergent behavior, since emergent phenomena includes risks as well as abilities. I’d love to discuss more with you on twitter or at the next conference!
Thanks Tatsunori Hashimoto, Percy Liang, and Rishi Bommasani for helpful discussions (and any critiques on this blog should go to me, and not them).
Practicing AI research
I’m not a particularly experienced researcher (despite my title being “Senior” Research Scientist), but I’ve worked with some talented collaborators and spent a fair amount of time thinking about how to do research, so I thought I might write about how I go about it.
My perspective is this: doing research is a skill that can be learned through practice, much like sports or music.
The way I decompose research is into four skills: (1) idea conception and selection, (2) experiment design and execution, (3) writing the paper, and (4) maximizing impact. In other words, what differentiates good and bad researchers is these four skills.
Skill 1: Idea conception & selection.
The first skill in research is coming up with or choosing a topic to work on. This is basically “research taste”—everyone should choose the type of research that makes them feel fulfilled, but not all research tastes are equally impactful. I like research topics that are simple, general, and stand the test of time, and I try to avoid projects that are complicated, task-specific, or short-lived. A good suggestion from a friend is to either (1) work on a hot topic and do it better than everyone else, or (2) work on something that might become the next hot topic. Strategy 1 is lower risk and requires working very hard. Strategy 2 is higher risk but has potentially very high reward. When starting out, it can be reasonable to ask experienced researchers about their interests, and just work on the topics they find exciting.
Most people (including me) would benefit greatly by spending more time on idea selection, since doing this well is a huge multiplier on research impact. Conversely, working on a narrow topic with little headroom caps the impact of the project, no matter how well it is executed. I’ve also learned that it’s important to identify sunk cost fallacies—when I realized that I wasn’t gaining much traction doing medical image AI research, I gave that up completely and started doing NLP.
Skill 2: Designing & executing experiments.
After deciding on a topic, the next step is to design and execute experiments to show that an idea works, or that a scientific question is answered. Designing experiments is typically straightforward, and as a check for rigor I like to present my results to colleagues and ask if I’ve missed anything. Executing experiments quickly is good because there is a high opportunity cost of time, and it can show collaborators that you’re committed to the project. That being said, it’s bad to trade off speed for quality, because it’s important to develop a reputation for doing rigorous and comprehensive experiments, and even brilliant ideas can be ruined by a messy execution.
Skill 3: Writing the paper.
The way that a paper is written can massively alter how it is received. At a high-level, I think carefully about how to frame experimental results in the broader context of the field, so that readers know why the results are important and how they can be used. I have explicit meetings with both co-authors and non-co-authors to work on the framing of the paper.
At a lower level, I spend quite a bit of effort to make my papers easily understandable. When writing for a broad audience, I make sure to give sufficient background so that non-experts will be able to follow the motivation of the paper. Most readers will only skim or look at a screenshot of a figure on twitter, so I spend more time on the abstract and introduction than other parts of the paper, and I make figures that stand alone. I try to use simple words and avoid jargon because much of the AI research community is not native English speakers.
Skill 4: Maximizing impact.
The final skill comes mostly after the paper is out, and it is maximizing the impact of your work. I think this is the most underrated skill and also the easiest to improve. There are many ways of maximizing impact, and it’s worth doing all of them—advertising the work on twitter, giving talks, presenting at conferences, writing follow-up papers, recording youtube videos, writing blog posts, etc. Advertising work on twitter is probably the highest return per amount of effort, and scales pretty well. Open-sourcing code, data, or model checkpoints is usually worth the time, since it allows other researchers to easily build on your work.
Aside from individual papers, it’s important to build personal branding. Having a website is certainly worth the time (yes, some famous people don’t have websites and I think they should). I started writing a personal technical blog, too. Just to underscore how much this skill is underrated, this is Richard Hamming’s suggestion: “I believed, in my early days, that you should spend at least as much time in the polish and presentation as you did in the original research. Now at least 50% of the time must go for the presentation. It's a big, big number.”
Meta-level
The above are what I consider to be the key skills in AI research. At the meta-level, finding a strong group of collaborators accelerates all four skills, as they can push you to choose great topics, give feedback on experiments and paper writing, and help promote your work. One of the things that I’ve gotten the most mileage out of is going out of my way to collaborate with certain researchers. Although it can be a bit stressful, working closely with an incredibly successful researcher has been a good forcing function for developing my research taste—they aren’t interested in incremental ideas. Such researchers are often busy, but I’ve found that they’re more receptive to give you their time if you work with their PhD students (if they’re a professor) or people they manage (if they’re at a company).
In addition to direct collaborations, I periodically try to identify the researchers I most admire, think about why I admire them, and try to learn those skills. For me, I’ve recently been a fan of Noam Shazeer, Jacob Devlin, Jeff Dean, Percy Liang, Barret Zoph, and Danqi Chen. (From this list, the common denominators seem to be working on broad problems, high technical ability, and working hard.)
Finally, I think that it’s important to have intermediate goals (the ultimate goal should be to advance AI). When I was starting out, my goal was simply to get as many conference acceptances as possible; while I think a goal like this is fine for applying to PhD programs or getting a job, I over-optimized for this a bit, which resulted in some of my incremental work in 2021. Citations alone as a goal can be a bit shallow, and twitter engagement is a bit too hype-focused. Maybe a combination of both input metrics (e.g., hours spent working) and output metrics (e.g., citations) is better, and I don’t have a perfect system for this, but having concrete goals can definitely help you focus on how you spend time.
There are definitely many ways of doing good research, and this is just my personal perspective and journey. I think this approach is pretty general, but skills 2 and 4 are quite specific to AI, and the skills change if you become a professor or manager. For better advice, I liked stuff written by Richard Hamming, John Schulman, Michael Neilsen, and Andrej Karpathy.
Thanks Shayne Longpre, Hyung Won Chung and Jerry Wei for feedback on this.
Research I enjoy
Doing research that is enjoyable is critical to producing outstanding work. Research is a long-term endeavor (done over decades!), involving challenges, failures, and drama. It will be hard to sustain a career doing work that is not enjoyable.
In this blog post I reflect on my work in the past few years, focusing in particular on how I feel about the papers I’ve written. I realized that I’m heavily motivated by how much impact my research has on the community, and so research that makes me happy roughly translates to the following things.
Research I enjoy…
Is about a general idea
Demonstrates thought leadership or influences the community
Aims towards artificial general intelligence (AGI)
Research I've done before and now try to avoid…
Is task-specific
Is not of interest to the general community
Has a weakness that could render it quickly stale
Reflecting on my work in the past few years, here are the papers that I look back fondly on:
Chain-of-thought prompting elicits reasoning in large language models, NeurIPS 2022. It’s easy for me to like this paper since Sundar presented it at Google I/O, but the real reasons I like chain of thought (CoT) are more intrinsic. For example, CoT can work for any task; CoT performance improves with model scale; and CoT does not require finetuning. In terms of impact, I think of CoT as a framework for how to prompt language models, and people have told me that it changed their minds about the kinds of tasks that language models can do.
Scaling instruction-finetuned language models, 2022. This paper scaled instruction finetuning in terms of number of tasks and model size. Although the empirical results were strong, the more important implication is that instruction finetuning is likely to stand the test of time and continue improving performance as we get more data and use better pre-trained models. The positive response from the community for our Flan-T5 models were also great to see. I also really liked the first Flan paper, but at this point is it seems basically like a trial run for this paper.
Emergent abilities of large language models, TMLR 2022. Although this paper has no experiments, I think the way that we presented emergent abilities put the existing literature together in a digestable way. The deeper point here is the implication that continued scaling may unlock even more abilities which are not present in small models. What's also special for me about this paper is that the framing went through 3-5 iterations with a diverse set of co-authors before we finally converged on the final one, and that process was a lot of fun.
Conversely, other papers I’ve worked on feel a bit less fulfilling now, for reasons that are clear in retrospect. (I feel bad to critique this work since it also represents co-authors, but I’m first author on all these so happy to take the hit for all the limitations. Also, I learned a lot from these projects and met amazing collaborators, so these papers were fulfilling in that aspect.)
Frequency effects on syntactic rule-learning in transformers, EMNLP 2021. In my view this paper was quite rigorous in the way the experiments were designed and executed, but the main limitation is that we only focused on a single model size and a single narrow task (subject-verb agreement). This niche setup hurt the generality of the paper quite a bit and made it unclear how to extrapolate the findings to other settings.
A cognitive regularizer for language modeling, ACL 2021. I liked this paper a lot when I wrote it, since it combines information theory with deep learning. In retrospect, the topic was too narrow for my taste. The maximum number of people who would be interested was only a subset of the NLP community, and the benefit of cognitive regularizers seems to diminish as we have more data. Similar critique for my other computational linguistics paper.
Easy data augmentation techniques for boosting performance on text classification tasks, EMNLP 2019. This paper garnered more than 1K citations at the time I write this blog post, and I do think there are some scenarios where data augmentation is critical. However, I am not sure that boosting performance by a few percent (which is basically the point of data augmentation) is a “game-changing” direction, especially since a lot of the gains go away with large data or model pre-training. Similar critique for my other data augmentation papers.
Overall, the biggest lesson I've learned is the importance of choosing a research style that makes me happy. The topic determines the best case scenario for the outcome of the research project, and if the topic is too narrow, the impact will be capped no matter how well it is executed.
(This blog post represents my personal opinions only, and not those of my employer.)
137 emergent abilities of large language models
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
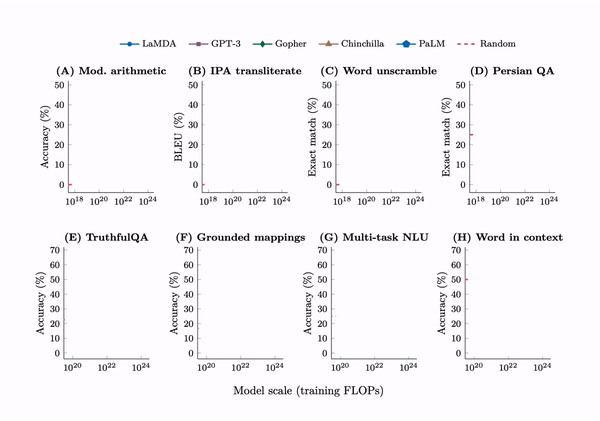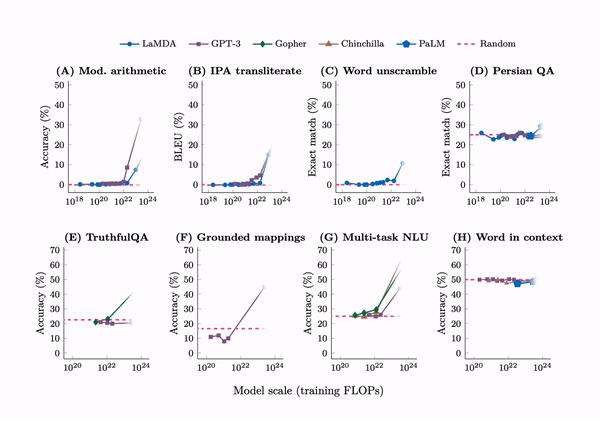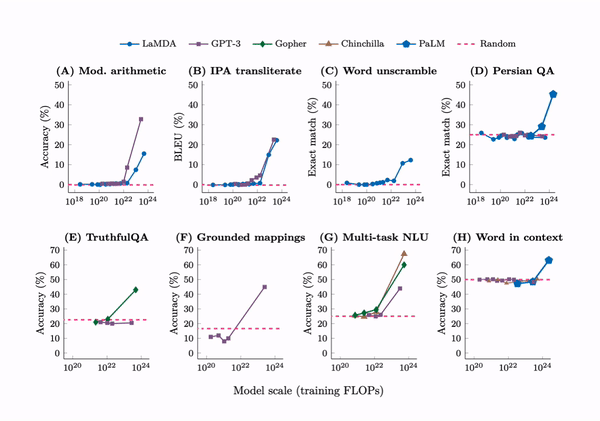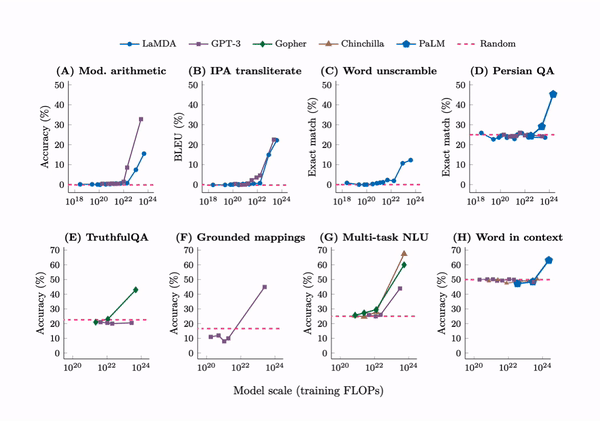
Emergent abilities are not present in small models but can be observed in large models.
In Emergent abilities of large language models, we defined an emergent ability as an ability that is “not present in small models but is present in large models.” Is emergence a rare phenomena, or are many tasks actually emergent?
It turns out that there are more than 100 examples of emergent abilities that already been empirically discovered by scaling language models such as GPT-3, Chinchilla, and PaLM. To facilitate further research on emergence, I have compiled a list of emergent abilities in this post.
Emergent few-shot prompted tasks
First, emergent few-shot prompted tasks have performance at random chance for small models and well above-random for large models. By far the largest sources for these emergent tasks were BIG-Bench and the Massive Multitask Benchmark, with 67 and 51 emergent tasks respectively. Here are the tasks:
BIG-Bench (67 tasks):
- GPT-3 13B (2 tasks): hindu knowledge, modified arithmetic
- GPT-3 175B (15 tasks): analytic entailment, codenames, phrase relatedness, question answer creation, self evaluation tutoring, common morpheme, fact checker, figure of speech detection, international phonetic alphabet transliterate, logical deduction, misconceptions, physical intuition, social iqa, strange stories, strategyqa
- LaMDA 137B (8 tasks): gender inclusive sentences german, repeat copy logic, sports understanding, swahili english proverbs, word sorting, word unscrambling, irony identification, logical args
- PaLM 8B (3 tasks): auto debugging, sufficient information, parsinlu reading comprehension
- PaLM 64B (14 tasks): anachronisms, ascii word recognition, conceptual combinations, cryptonite, disambiguation qa, emoji movie, goal step wikihow, gre reading comprehension, linguistics puzzles, logic grid puzzle, metaphor understanding, odd one out, metaphor boolean, parsinlu qa
- PaLM 540B (25 tasks): analogical similarity, causal judgment, code line description, crass ai, cs algorithms, elementary math qa, english russian proverbs, geometric shapes, hyperbaton, identify odd metaphor, international phonetic alphabet nli, language identification, logical fallacy detection, logical sequence, movie dialog same or different, physics questions, question selection, temporal sequences, understanding fables, unit interpretation, snarks, english proverbs, timedial, hinglish toxicity, vitaminc fact verification
MMLU (51 tasks; see the Chinchilla paper for results):
- Chinchilla 7B (7 tasks): Professional Medicine, High School Statistics, High School Macroeconomics, High School Psychology, Anatomy, High School Government And Politics, High School Microeconomics
- Chinchilla 70B (44 tasks): International Law, Human Aging, Sociology, Us Foreign Policy, High School World History, Marketing, Logical Fallacies, Miscellaneous, College Biology, High School Us History, Security Studies, High School European History, High School Geography, Computer Security, Human Sexuality, Astronomy, Prehistory, Philosophy, Jurisprudence, Management, Moral Disputes, High School Biology, Professional Psychology, World Religions, Nutrition, Clinical Knowledge, Business Ethics, Medical Genetics, High School Computer Science, Public Relations, College Medicine, Conceptual Physics, Electrical Engineering, High School Chemistry, Machine Learning, Professional Accounting, Professional Law, Virology, Econometrics, College Physics, Elementary Mathematics, Moral Scenarios, Formal Logic, High School Physics
In addition to these large repositories of tasks, several papers have also shown individual tasks as emergent abilities:
GPT-3 paper: 3 digit addition/subtraction (GPT-3 13B), 4-5 digit addition/substraction (GPT-3 175B), leveraging few-shot examples for word denoising (GPT-3 13B)
Gopher paper: Toxicity classification (Gopher 7.1B), TruthfulQA (Gopher 280B)
Patel & Pavlick: grounded conceptual mappings (GPT-3 175B)
PaLM paper: Word in Context benchmark (PaLM 540B)
Emergent prompting strategies
Whereas emergent prompted tasks focus on a particular dataset, the second category of emergence is few-shot prompting strategies, which are general prompting strategies that only work for language models of a sufficiently large scale. These are the emergent prompting strategies that I have seen so far in the literature.
Instruction-following (FLAN 68B): finetuning on instructions enables zero-shot generalization to unseen tasks
Scratchpad (LaMDA 40M): training language models to execute algorithms by predicting the intermediate states line-by-line
Using open-book knowledge for fact checking (Gopher 7B): leveraging gold evidence to improve performance
Chain-of-thought prompting (LaMDA 68B): language models can perform multi-step reasoning by generating a chain of thought before giving the final answer
Differentiable search index (T5 11B): information retrieval with corpus encoded in the parameters
Self-consistency (LaMDA 68B): taking the majority vote of randomly sampled chain-of-thought generations
Leveraging explanations in prompting (Gopher 280B): including explanations in few-shot examples improve performance
Least-to-most prompting (GPT-3 175B): multi-stage hierarchical reasoning for complex reasoning
Zero-shot chain-of-thought (GPT-3 175B): solving math word problems with the prompt “Let’s think step-by-step”
Calibration via P(True) (Anthropic LM 52B): better calibration by asking the language model the P(True) for an answer
Multilingual chain-of-thought (PaLM 62B): solving multi-step math problems in under-represented languages
Ask-me-anything prompting (GPT-Neo 6B): prompt ensembles improve performance
Looking forward
Given these new abilities of language models, I think there are several promising future research directions, beyond simply scaling up.
Can we improve model architectures? E.g., sparsity, external memory, better objectives
Can we improve data quality and quantity? Training for longer increases pre-training compute but not inference compute
Better prompting. How can we extract the most performance out of an existing language model?
Frontier tasks. What tasks are language models currently not able to perform, that we should evaluate on future language models of better quality?
Why do emergent abilities occur, and can we predict them? E.g., do language models learning compositional abilities that enable them to solve harder problems?
Overall, the existence of emergent abilities applies that scaling further would unlock even more emergent abilities. This idea is super exciting to me. If I missed any emergent abilities, feel free to email me and I’ll add them to the list! jason.weng.wei@gmail.com
Thanks Yi Tay for feedback on this blog post.