137 emergent abilities of large language models
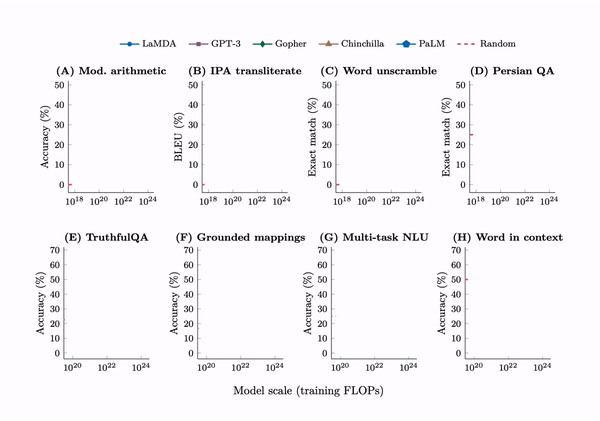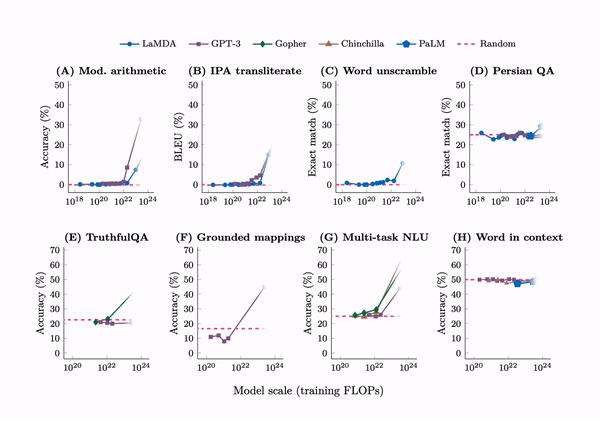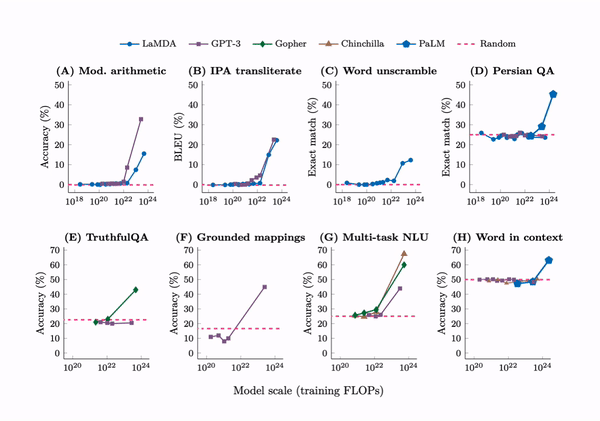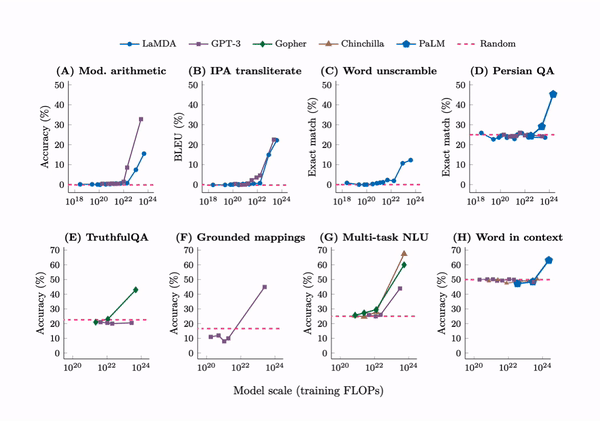
Emergent abilities are not present in small models but can be observed in large models.
In Emergent abilities of large language models, we defined an emergent ability as an ability that is “not present in small models but is present in large models.” Is emergence a rare phenomena, or are many tasks actually emergent?
It turns out that there are more than 100 examples of emergent abilities that already been empirically discovered by scaling language models such as GPT-3, Chinchilla, and PaLM. To facilitate further research on emergence, I have compiled a list of emergent abilities in this post.
Emergent few-shot prompted tasks
First, emergent few-shot prompted tasks have performance at random chance for small models and well above-random for large models. By far the largest sources for these emergent tasks were BIG-Bench and the Massive Multitask Benchmark, with 67 and 51 emergent tasks respectively. Here are the tasks:
BIG-Bench (67 tasks):
- GPT-3 13B (2 tasks): hindu knowledge, modified arithmetic
- GPT-3 175B (15 tasks): analytic entailment, codenames, phrase relatedness, question answer creation, self evaluation tutoring, common morpheme, fact checker, figure of speech detection, international phonetic alphabet transliterate, logical deduction, misconceptions, physical intuition, social iqa, strange stories, strategyqa
- LaMDA 137B (8 tasks): gender inclusive sentences german, repeat copy logic, sports understanding, swahili english proverbs, word sorting, word unscrambling, irony identification, logical args
- PaLM 8B (3 tasks): auto debugging, sufficient information, parsinlu reading comprehension
- PaLM 64B (14 tasks): anachronisms, ascii word recognition, conceptual combinations, cryptonite, disambiguation qa, emoji movie, goal step wikihow, gre reading comprehension, linguistics puzzles, logic grid puzzle, metaphor understanding, odd one out, metaphor boolean, parsinlu qa
- PaLM 540B (25 tasks): analogical similarity, causal judgment, code line description, crass ai, cs algorithms, elementary math qa, english russian proverbs, geometric shapes, hyperbaton, identify odd metaphor, international phonetic alphabet nli, language identification, logical fallacy detection, logical sequence, movie dialog same or different, physics questions, question selection, temporal sequences, understanding fables, unit interpretation, snarks, english proverbs, timedial, hinglish toxicity, vitaminc fact verification
MMLU (51 tasks; see the Chinchilla paper for results):
- Chinchilla 7B (7 tasks): Professional Medicine, High School Statistics, High School Macroeconomics, High School Psychology, Anatomy, High School Government And Politics, High School Microeconomics
- Chinchilla 70B (44 tasks): International Law, Human Aging, Sociology, Us Foreign Policy, High School World History, Marketing, Logical Fallacies, Miscellaneous, College Biology, High School Us History, Security Studies, High School European History, High School Geography, Computer Security, Human Sexuality, Astronomy, Prehistory, Philosophy, Jurisprudence, Management, Moral Disputes, High School Biology, Professional Psychology, World Religions, Nutrition, Clinical Knowledge, Business Ethics, Medical Genetics, High School Computer Science, Public Relations, College Medicine, Conceptual Physics, Electrical Engineering, High School Chemistry, Machine Learning, Professional Accounting, Professional Law, Virology, Econometrics, College Physics, Elementary Mathematics, Moral Scenarios, Formal Logic, High School Physics
In addition to these large repositories of tasks, several papers have also shown individual tasks as emergent abilities:
GPT-3 paper: 3 digit addition/subtraction (GPT-3 13B), 4-5 digit addition/substraction (GPT-3 175B), leveraging few-shot examples for word denoising (GPT-3 13B)
Gopher paper: Toxicity classification (Gopher 7.1B), TruthfulQA (Gopher 280B)
Patel & Pavlick: grounded conceptual mappings (GPT-3 175B)
PaLM paper: Word in Context benchmark (PaLM 540B)
Emergent prompting strategies
Whereas emergent prompted tasks focus on a particular dataset, the second category of emergence is few-shot prompting strategies, which are general prompting strategies that only work for language models of a sufficiently large scale. These are the emergent prompting strategies that I have seen so far in the literature.
Instruction-following (FLAN 68B): finetuning on instructions enables zero-shot generalization to unseen tasks
Scratchpad (LaMDA 40M): training language models to execute algorithms by predicting the intermediate states line-by-line
Using open-book knowledge for fact checking (Gopher 7B): leveraging gold evidence to improve performance
Chain-of-thought prompting (LaMDA 68B): language models can perform multi-step reasoning by generating a chain of thought before giving the final answer
Differentiable search index (T5 11B): information retrieval with corpus encoded in the parameters
Self-consistency (LaMDA 68B): taking the majority vote of randomly sampled chain-of-thought generations
Leveraging explanations in prompting (Gopher 280B): including explanations in few-shot examples improve performance
Least-to-most prompting (GPT-3 175B): multi-stage hierarchical reasoning for complex reasoning
Zero-shot chain-of-thought (GPT-3 175B): solving math word problems with the prompt “Let’s think step-by-step”
Calibration via P(True) (Anthropic LM 52B): better calibration by asking the language model the P(True) for an answer
Multilingual chain-of-thought (PaLM 62B): solving multi-step math problems in under-represented languages
Ask-me-anything prompting (GPT-Neo 6B): prompt ensembles improve performance
Looking forward
Given these new abilities of language models, I think there are several promising future research directions, beyond simply scaling up.
Can we improve model architectures? E.g., sparsity, external memory, better objectives
Can we improve data quality and quantity? Training for longer increases pre-training compute but not inference compute
Better prompting. How can we extract the most performance out of an existing language model?
Frontier tasks. What tasks are language models currently not able to perform, that we should evaluate on future language models of better quality?
Why do emergent abilities occur, and can we predict them? E.g., do language models learning compositional abilities that enable them to solve harder problems?
Overall, the existence of emergent abilities applies that scaling further would unlock even more emergent abilities. This idea is super exciting to me. If I missed any emergent abilities, feel free to email me and I’ll add them to the list! jason.weng.wei@gmail.com
Thanks Yi Tay for feedback on this blog post.